

事件是系统发送的消息,用于通知操作员或其他系统有关其域中的更改。随着由 Apache Kafka等系统提供支持的事件驱动架构变得越来越突出,现代软件堆栈中有许多应用程序利用事件和消息进行有效操作。在这个博客中,我们将研究三个不同的数据后端对事件数据的使用 – Apache Druid、弹性搜索和岩集。
使用事件数据
系统通常以下列方式使用事件:
- 用于响应其他系统中的更改:例如,付款完成后,会向用户发送收据。
- 记录随后可用于根据需要重新计算状态的更改:例如事务日志。
- 支持数据访问(读/写)机制(如CQRS)的分离。
- 帮助理解和分析系统的当前和过去状态。
我们将重点使用事件来帮助理解、分析和诊断应用程序和业务流程中的瓶颈,同时使用Druid、Elasticsearch和Rockset与 Kafka 这样的流式处理平台。
您可能还喜欢:实时流处理与阿帕奇卡夫卡第一部分。
事件数据类型
应用程序发出与其上下文中的重要操作或状态更改相对应的事件。此类事件的一些示例包括:
- 对于航空公司价格聚合器,当用户预订航班时、与航空公司确认预订、用户取消预订、退款完成时等,都生成事件。
// an example event generated when a reservation is confirmed with an airline.
{
"type": "ReservationConfirmed"
"reservationId": "RJ4M4P",
"passengerSequenceNumber": "ABC123",
"underName": {
"name": "John Doe"
},
"reservationFor": {
"flightNumber": "UA999",
"provider": {
"name": "Continental",
"iataCode": "CO",
},
"seller": {
"name": "United",
"iataCode": "UA"
},
"departureAirport": {
"name": "San Francisco Airport",
"iataCode": "SFO"
},
"departureTime": "2019-10-04T20:15:00-08:00",
"arrivalAirport": {
"name": "John F. Kennedy International Airport",
"iataCode": "JFK"
},
"arrivalTime": "2019-10-05T06:30:00-05:00"
}
}
- 对于电子商务网站,从配送中心发货到买方接收,在发货时生成的事件将经历每个阶段。
// example event when a shipment is dispatched.
{
"type": "ParcelDelivery",
"deliveryAddress": {
"type": "PostalAddress",
"name": "Pickup Corner",
"streetAddress": "24 Ferry Bldg",
"addressLocality": "San Francisco",
"addressRegion": "CA",
"addressCountry": "US",
"postalCode": "94107"
},
"expectedArrivalUntil": "2019-10-12T12:00:00-08:00",
"carrier": {
"type": "Organization",
"name": "FedEx"
},
"itemShipped": {
"type": "Product",
"name": "Google Chromecast"
},
"partOfOrder": {
"type": "Order",
"orderNumber": "432525",
"merchant": {
"type": "Organization",
"name": "Bob Dole"
}
}
}
- 对于 IoT 平台,当设备注册、联机、报告正常、需要修复/更换等时生成的事件
{
“设备Id”:”529d0ea0-e702-11e9-81b4-2a2ae2dbcce4″,
“时间戳”:”2019-10-04T23:56:59+0000″,
“状态”:”在线”,
“加速”: |
“accelX”:”0.522″,
“accelY”:”-.005″,
“accelZ”:”0.4322”
},
“温度”: 77.454,
“电位计”: 0.0144
}
这些类型的事件可以提供对特定系统或业务流程的可见性。它们可以帮助回答有关特定实体(用户、货件或设备)的问题,以及在特定时间范围内快速支持潜在问题的分析和诊断。
构建事件分析
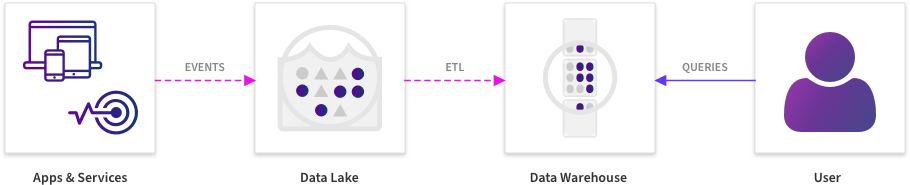
过去,此类事件会流式传输到数据湖中,并被引入数据仓库,然后交给 BI/数据科学工程师来挖掘模式数据。
之前
后
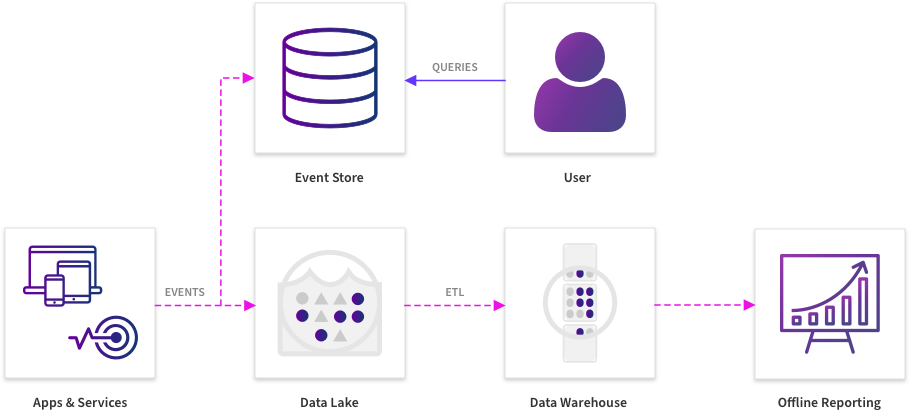
随着新一代数据基础架构的变化,这种情况已经改变,因为快速、及时地响应这些事件的变化对成功至关重要。在每一秒不可用都会造成收入损失的情况下,了解模式和缓解对系统或流程运行状况产生不利影响的问题已成为时间关键练习。
当需要尽可能实时地分析和诊断时,必须重新考虑帮助执行事件分析的系统的要求。有一些工具专门在特定领域执行事件分析,例如产品分析和点击流分析,但考虑到企业的特定需求,我们通常希望构建特定于业务或流程的自定义工具,允许用户根据这些事件快速了解并根据需要采取行动。
在很多情况下,这样的系统都是通过组合不同的技术(包括流式管道、湖泊和仓库)而构建的。在提供服务查询时,这需要具有以下属性的分析后端:
- 快速引入– 即使每秒有数十万个事件流动,但用于促进事件数据分析的后端也必须能够跟上该速率。复杂的脱机 ETL 进程不可取,因为它们会在数据可供查询之前将分钟添加到几小时。
- 交互式延迟– 系统必须允许实时临时查询和向下钻取。有时,理解事件中的模式需要能够按事件中的不同属性进行分组,以尝试并实时了解相关性。
- 复杂查询– 系统必须允许使用富有表现力的查询语言进行查询,以允许表示值查找、对谓词进行筛选、聚合函数和联接。
- 开发人员友好– 系统必须附带库和 SDK,允许开发人员在其之上编写自定义应用程序,并支持仪表板。
- 可配置和可扩展– 这包括能够控制保留记录的时间、查询的数据副本数,以及能够以最小的操作开销扩展以支持更多数据。
德鲁伊
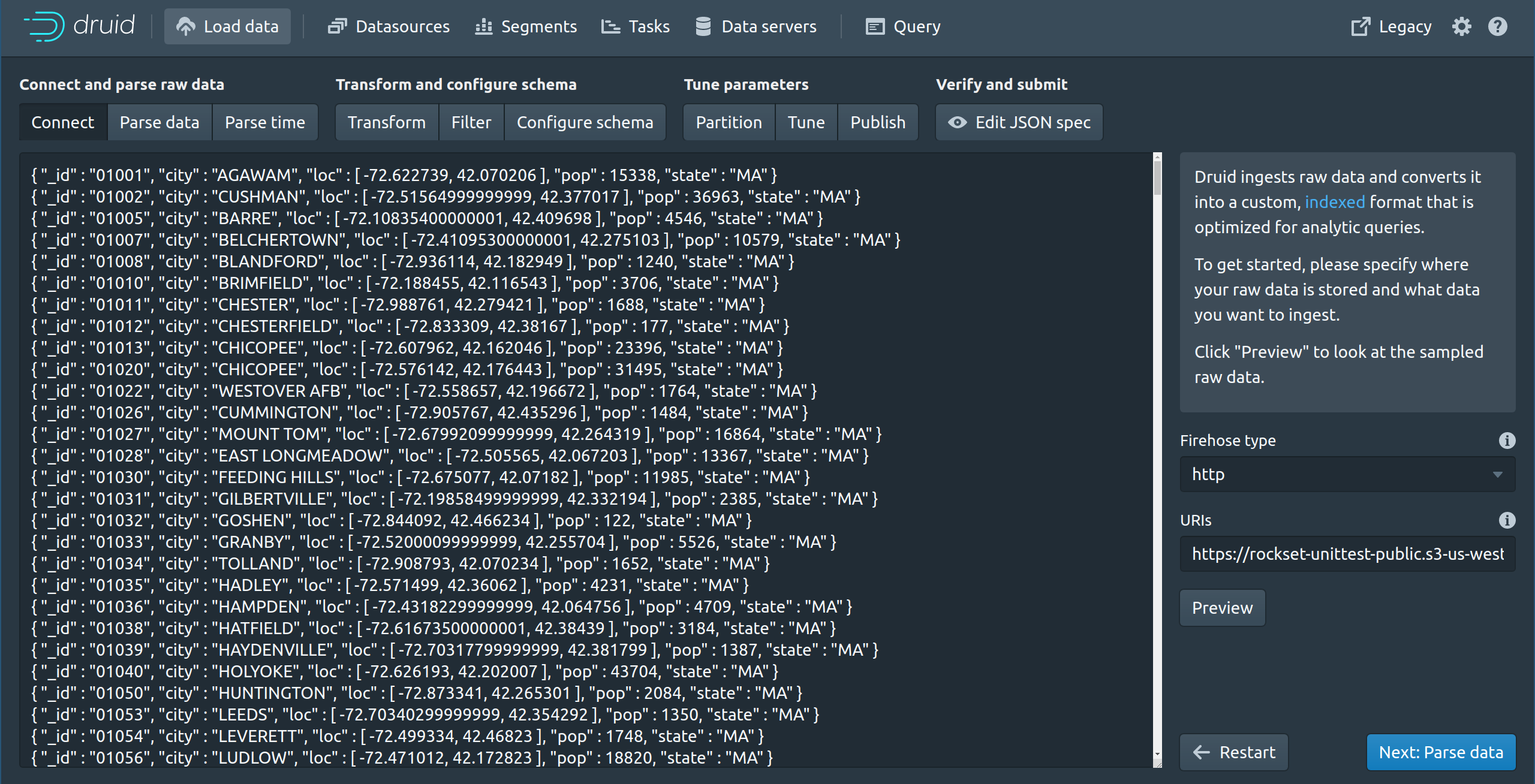
在此示例中,我们将一组 JSON 事件插入到 Druid 中。Druid 不支持嵌套数据,因此,我们需要通过提供拼合规范或在事件登陆之前执行一些预处理来拼合 JSON 事件中的数组。
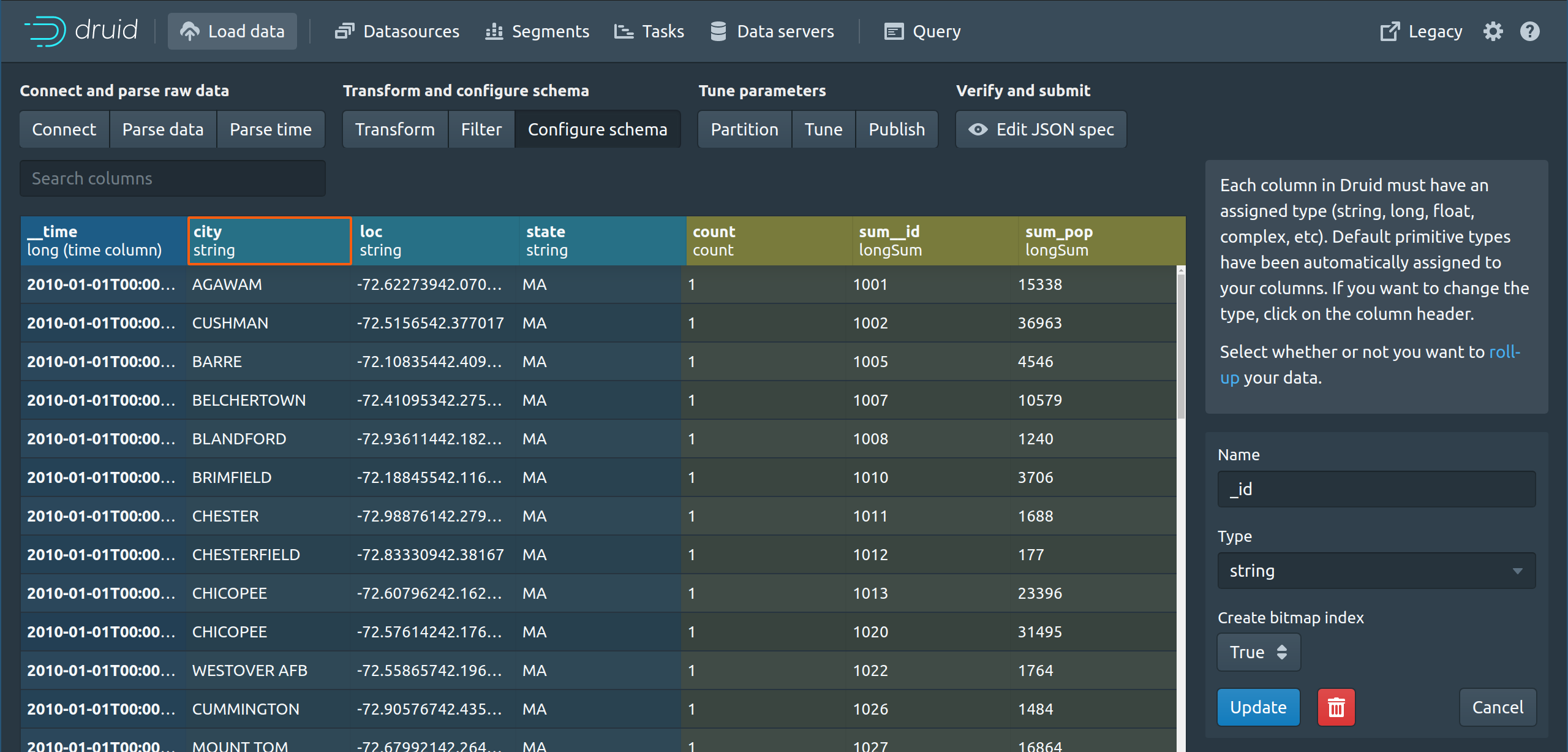
Druid 将类型分配给列 = 字符串、长列、浮点列、复合列等。如果传入数据为特定字段/字段提供混合类型,则列级别的类型强制可能受到限制。除时间戳外,每列都可以为类型维度或指标。
可以按维度列进行筛选和分组,但不能在指标列上进行筛选和分组。这在选取要预聚合的列以及哪些列将用于切片和骰子分析时需要一些预先考虑。
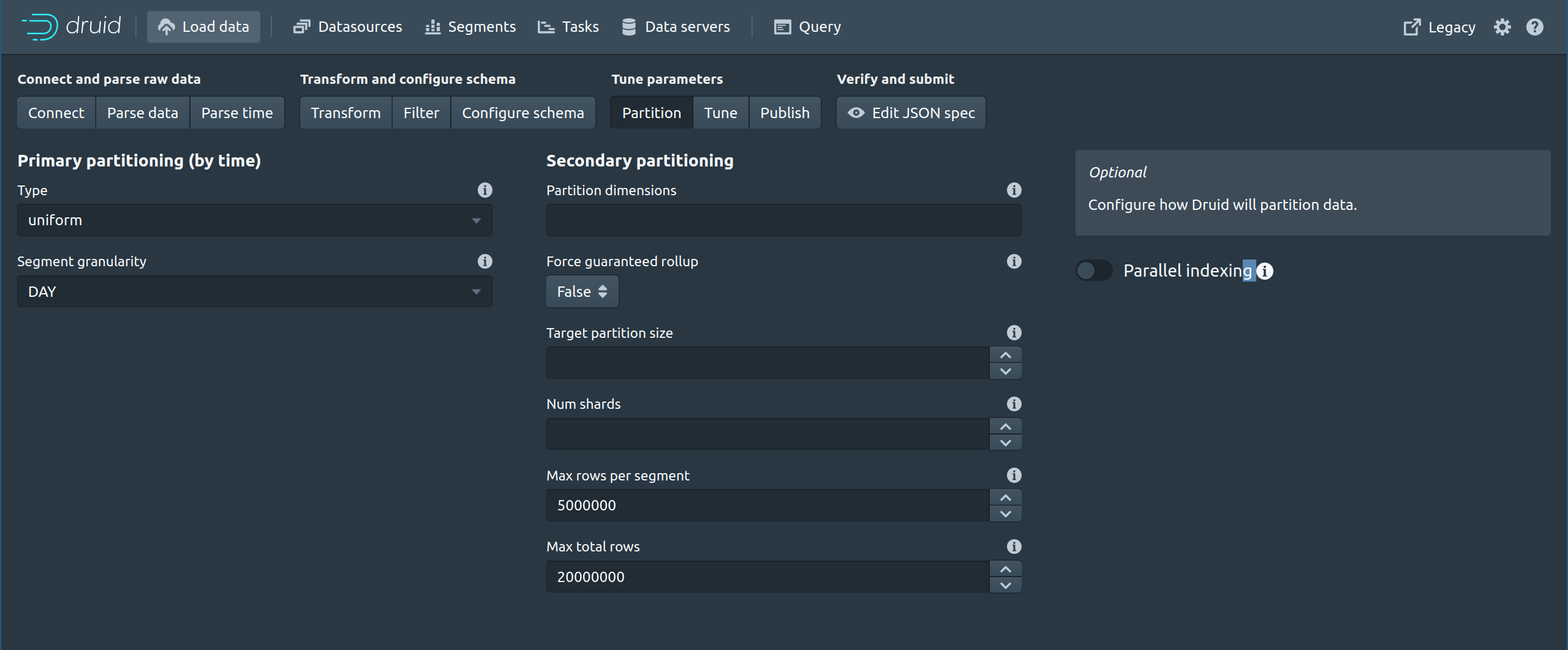
必须仔细选取分区键,以便进行负载平衡和向上扩展。创建后将新更新流式传输到表需要使用支持的引入方法之一 – Kafka、Kinesis 或”宁静”。
Druid 非常适合在数据有些可预测的环境中进行事件分析,并且可以先验地定义汇总和预聚合。它涉及一些工程方面的维护和调整开销,但对于不涉及复杂联接的事件分析,它可以以低延迟处理查询,并根据需要进行扩展。
总结
- 对列存储的低延迟分析查询。
- 引入时间聚合有助于减少写入的数据量。
- 对不同编程语言的 SDK 和库的良好支持。
- 与 Hadoop 配合良好。
- 列级别的类型强制可以限制混合类型。
- 规模从中到高运营开销。
- 估计资源和容量规划在规模上是困难的。
- 缺少对嵌套数据本机的支持。
- 缺乏对 SQL JOIN 的支持。
弹性搜索
弹性搜索是一个搜索和分析引擎,也可用于对事件数据的查询。弹性搜索因其全文搜索功能而对系统和计算机日志进行查询时最为流行,在某些特定情况下,弹性搜索可用于临时分析。
弹性搜索建立在 Apache Lucene 之上,通常与 Logstash 一起使用,用于引入数据,而 Kibana 则用作报告数据的仪表板
弹性搜索索引引入数据,这些索引通常被复制,并用于为查询提供服务。弹性搜索查询 DSL 主要用于开发目的,尽管 X-Pack 中支持针对弹性搜索中的索引的某些类型的 SQL 分析查询的SQL 支持。这是必要的,因为对于事件分析,我们希望以通用的方式进行查询。
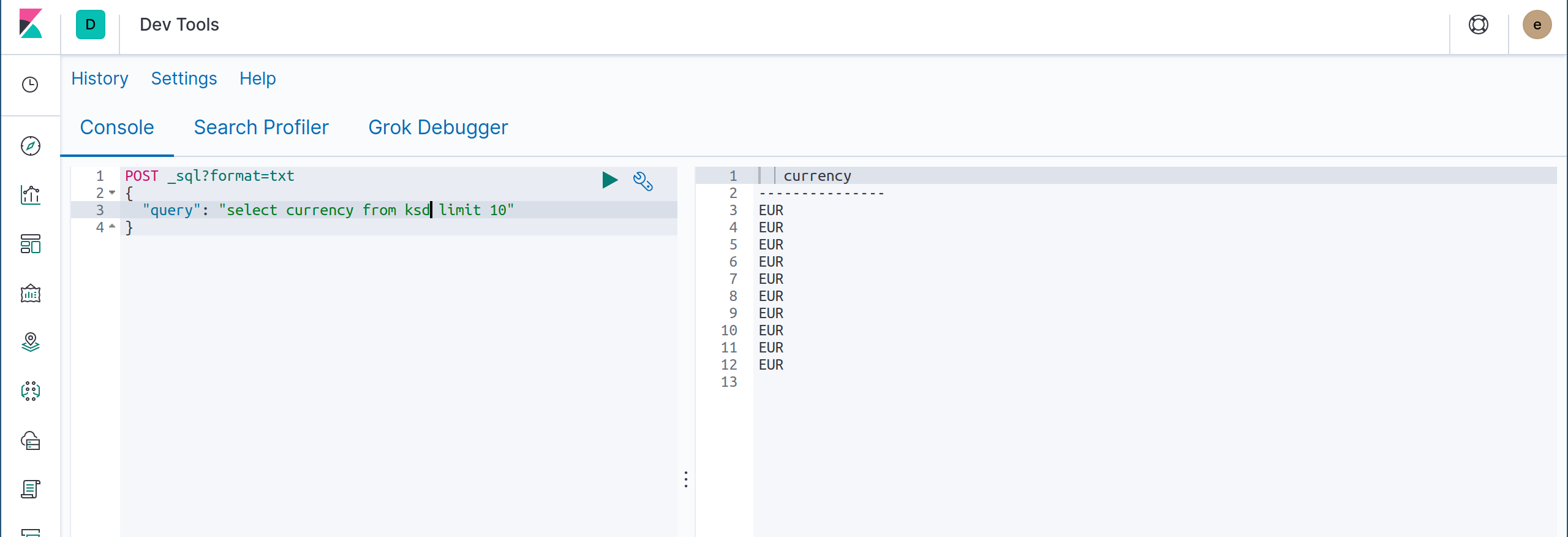
弹性搜索 SQL 适用于基本 SQL 查询,但当前不能用于查询嵌套字段,或运行涉及更复杂的分析(如关系 JOIN)的查询。这部分是由于基础数据模型。
可以使用弹性搜索进行一些基本的事件分析,Kibana 是一个优秀的视觉探索工具。但是,对 SQL 的有限支持意味着,在有效查询数据之前,可能需要对数据进行预处理。此外,在运行和维护引入管道和弹性搜索本身时,它还有不小的开销。因此,虽然它足以用于基本分析和报告,但其数据模型和受限查询功能使其无法成为事件数据的全功能分析引擎。
摘要:
- 出色的支持全文搜索。
- 由于索引颠倒,点查找的高效性。
- 丰富的 SDK 和库支持。
- 缺乏对 JOIN 的支持。
- 分析查询的 SQL 支持是新兴的,并且没有完全功能。
- 大规模高运营开销。
- 估计资源和容量规划是困难的。
岩石集
Rockset 是事件流分析的后端,可用于构建自定义工具,以便进行可视化、理解和向下钻取。它基于 RocksDB 构建,经过优化,可运行数十到数百 TB 的事件数据的搜索和分析查询。
将事件引入 Rockset 可以通过集成来完成,这些集成只需要在云中读取权限,或者直接使用JSON Write API写入 Rockset。
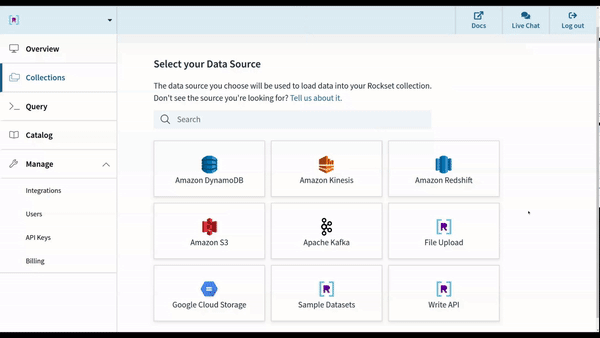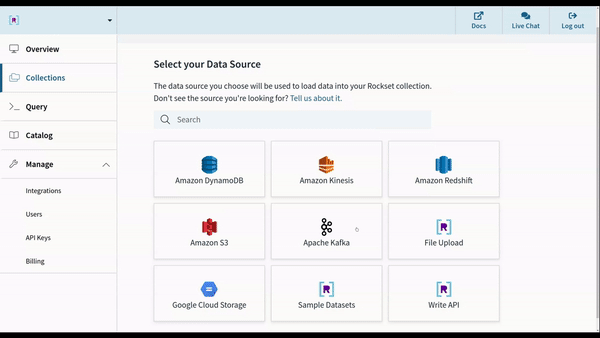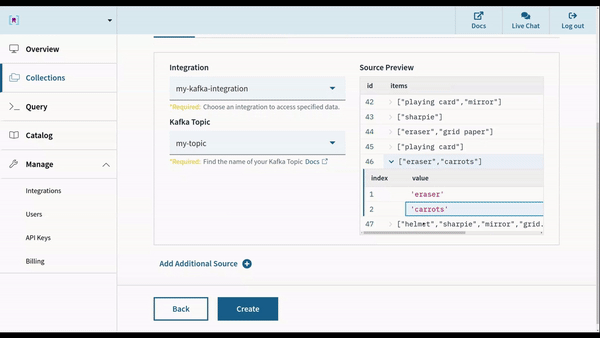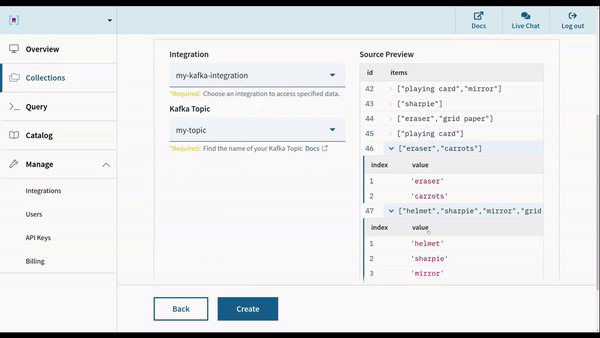
这些事件在几秒钟内处理,索引并可供查询。在引入期间,可以使用字段映射和基于 SQL 函数的转换预处理数据。但是,对于任何复杂的事件结构,无需进行预处理 ,对嵌套字段和混合类型列具有本机支持。
岩集支持使用 SQL,能够执行复杂的 JOIN。有一些 API 和语言库允许自定义代码连接到 Rockset 并使用 SQL 来构建一个可以执行自定义向下钻取和其他自定义功能的应用程序。使用聚合索引(该索引索引)索引列存储中的每个字段、搜索索引和其他自定义索引(用于地理数据等),临时查询利用所有这些索引快速运行完成。
利用对于实时事件数据的快速临时分析,Rockset 可通过使用完整 SQL 提供查询、连接器(如 Tableau、Redash、Superset 和 Grafana)以及通过 REST API 和不同语言的 SDK 进行编程访问来提供帮助。
摘要:
- 针对点查找和复杂分析查询进行了优化
- 支持完整的 SQL,包括分布式 JOIN
- 用于流和数据湖的内置连接器
- 无需容量估计 – 自动缩放
- 支持不同编程语言的 SDK 和库
- 低操作开销
- 小型数据集永久免费
- 作为托管服务提供
在这里,您可以看到复杂的分析查询如何使用 Rockset 处理 200 GB 的示例数据集。有关在 Kafka 事件流上构建实时仪表板和 API 的更多信息,请访问我们的Kafka 解决方案页面。
引用
- https://tech.ebayinc.com/engineering/monitoring-at-ebay-with-druid/
- https://blog.cloudflare.com/how-cloudflare-analyzes-1m-dns-queries-per-second/#comment-3302778860
- https://medium.com/engineering-tyroo/using-elasticsearch-for-reporting-analytics-3bb1d7c84c19