
导语
本文根据范良泽老师在2019年10月31日【第十一届中国系统架构师大会(SACC)】现场演讲内容整理而成。

2008年毕业于上海交通大学,曾供职于华为、Opera Solutions等公司,服务于通信、咨询、金融、地产等领域,一直从事研发相关工作。目前在中移物联网有限公司就职,负责连接管理平台OneLink平台研发工作,通过引入大数据、微服务、DevOps等技术和最佳实践,构筑全球最大的连接管理平台。
摘要:近几年物联网行业迎来爆发,用户规模持续指数级增长,OneLink平台经过架构和容量不断优化升级,到2019年8月已经成功支撑10万企业、5亿 用户,逐步成长为全球用户规模最大的连接管理平台,为人们日常工作和生活保驾护航。
本文主要分享大数据、微服务和DevOps等技术在OneLink成长和架构演进过程中的应用及实战经验,包括:
1、OneLink系统简介和成长挑战
2、用户从0到3千万到1亿再到5亿的架构演进
3、百亿级RADIUS报文业务优化方案和重难点技术
4、厚平台薄应用和两地三中心的灾备架构建设
OneLink 背景介绍
中移物联网有限公司,是中国移动通信集团公司出资成立的全资子公司,有五大核心业务:智能连接、芯片模组、开放平台、智能硬件、行业应用。
中国移动公众物联网连接管理平台(OneLink),通过专属的通信网元设备,以高品质、广覆盖的通信接入,满足物联网业务“规模性、流动性、安全性、稳定性”的特殊需求。为客户提供物联网连接管理服务,为合作伙伴提供产品引入代销结算服务,为省公司提供运营支撑服务。
2015年,我刚刚到公司时,大概在几百万不到一千万的物联网用户,现在有5亿多的物联网用户。
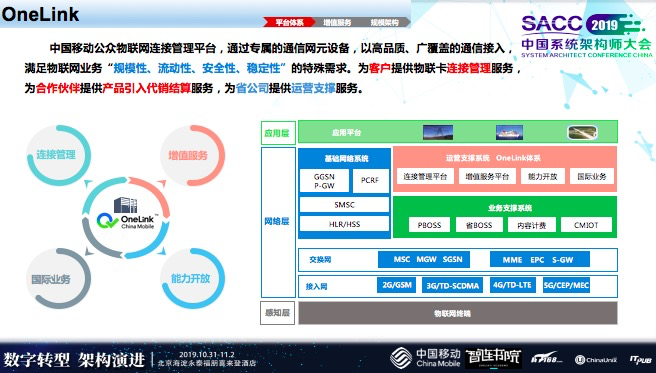
OneLink体系,主要涉及四个较大部分:
连接管理;
增值服务;
能力开放;
国际业务;
增值服务是与大家有合作空间的场景,现在已经提供的能力有:智能出入、移动商旅、健康管理、智慧金融、智能制造,安全服务。
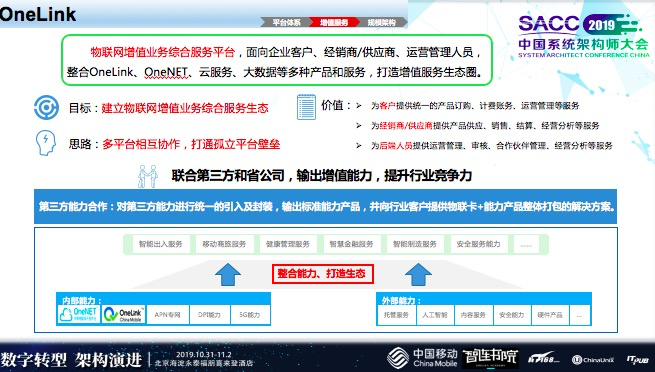
这些服务源自我们内部能力,外部客户及合作伙伴引入的一些能力,形成了对外的行业标准能力。
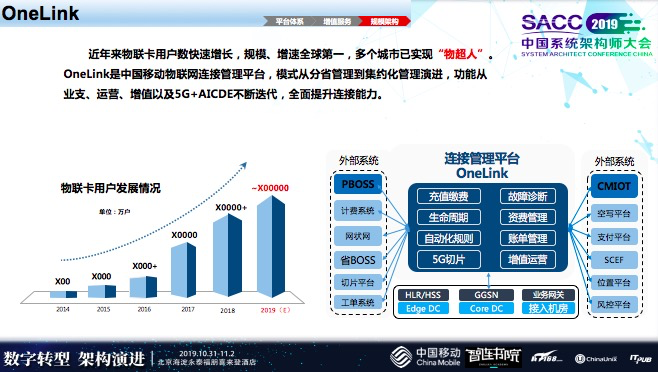
业务的发展推动了我们的架构演进,从2014年开始的百万级,到2019年5亿多,业务量猛增,让对外部交互变得越来越复杂。
那么,用户从0到百万千万再到5亿,我们的架构是怎么演进的?
架构演进
应用服务演进
从百万到千万带来的压力在于,大量数据业务的计算和存储都是基于Oracle处理,Oracle在数据量较大时,大量统计报表会影响到前台业务查询的状况,响应时间会下降,把计算资源吃掉了很多,所以查询响应时间会降下来。

对此,我们做的改变是引入了大数据技术,用Hadoop架构来完成计算和存储的演进,这一部分细节我就不再细讲了,前面很多老师也提到了这一点。
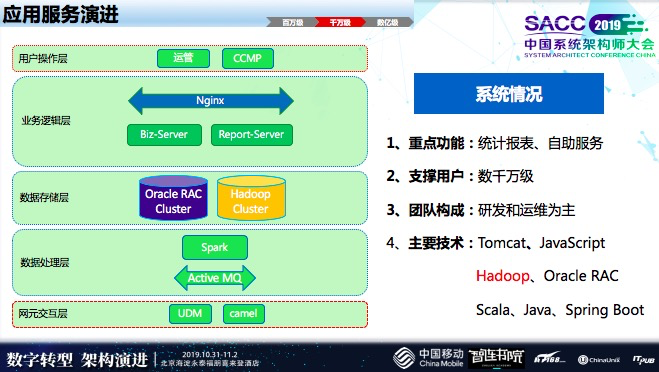
而到了数亿级时,最大的变化是微服务以及存储这两块有变化。
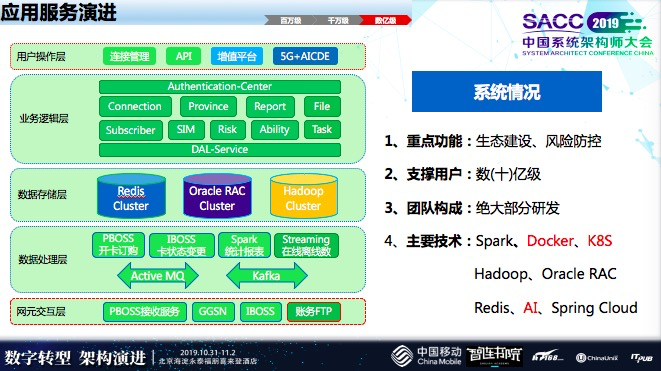
微服务引进新技术缓存,这样高频应用流量卸载,和外部网联的交互变得更系统,业务上面更清晰,同时也有一些人工智能的分析。
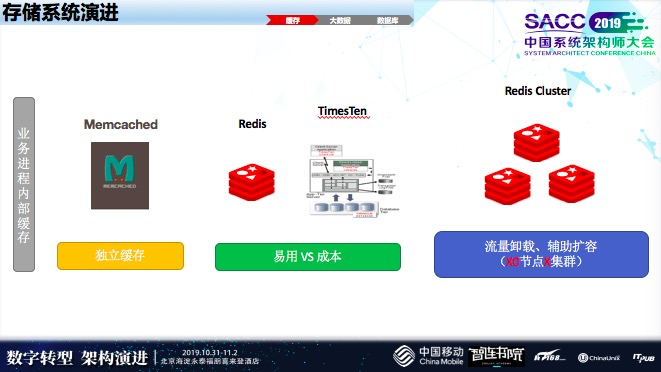
存储系统演进
最早,我们独立缓存和业务系统部署在统一虚拟机上。第二个阶段,在数千万的时候,Redis中间有一段时间尝试过TT,因为TT成本比较高,后来摒弃了。现在引用了RedisCluster来解决高频场景,目前大概有5到6个集群。
大数据架构中演进
早期,只处理日志类的业务,只涉及自身业务模块运行状况,比如运行状况分析、异常情况分析,当几千万级时,刚才提到,我们大数据集群缓解了Oracle的计算压力,当时,只用了存储还有报表以及上层查询的标准语句。
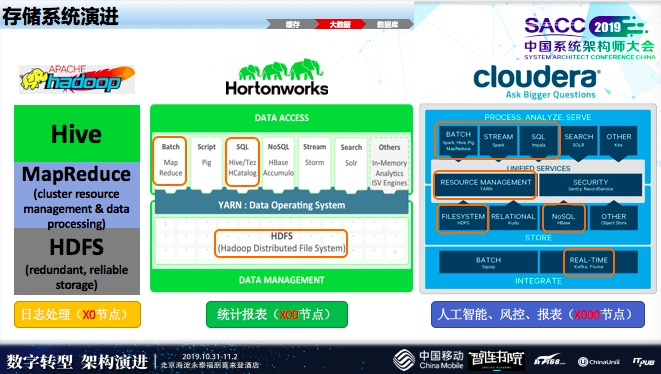
现在大数据已经变得很复杂了,有很多组件,包括流式统计、批处理以及人工智能,刚才提到,短时间内出现大量卡的状态,可能会有业务影响,我们通过人工智能办法把它识别出来。
像有些ToB场景,对流量的使用费用比较高,需要降一些成本,也会通过人工智能方法去把套餐做一些优化,这样的场景在现在大数据中就能完成。
最后,看一下数据库的演进,早期就是单库,把存储、查询还有统计报表计算都统一放到一个单库里。到了几千万的时候就出现瓶颈,把一部分计算逻辑挪到了Hadoop上,同时,重庆放到一个库里,北京放到一个库里。有的省份就已经是7000万、8000万接近上亿的用户量,这种情况下带来很大的压力。
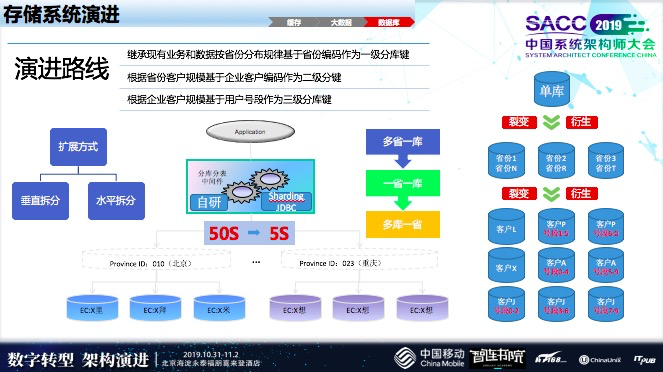
第二、是按照用户拆分、客户拆分,这样会降低性能负担。通过不断的演进,我们数据库渐渐完成了拆分,或者说分布式中间件来完成我们数据库的演进。这部分求是我们的数据库的变化的状况。
灾备建设演进
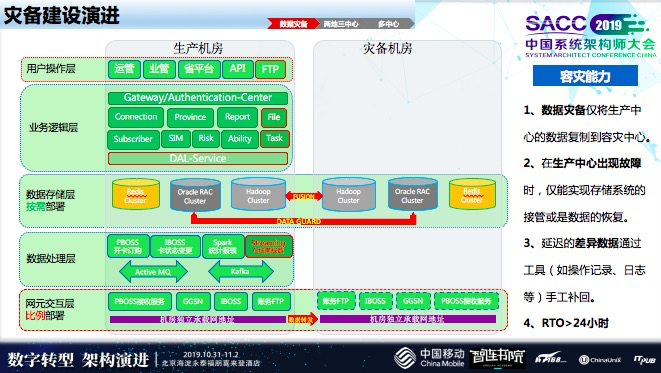
早期,大概几十万级别时,只做数据备份,外部的数据直接转发到异地的机房,只做数据的冷备,如果说机房出了问题,这个数据还在,但恢复可能就这个维度,恢复这个机房。
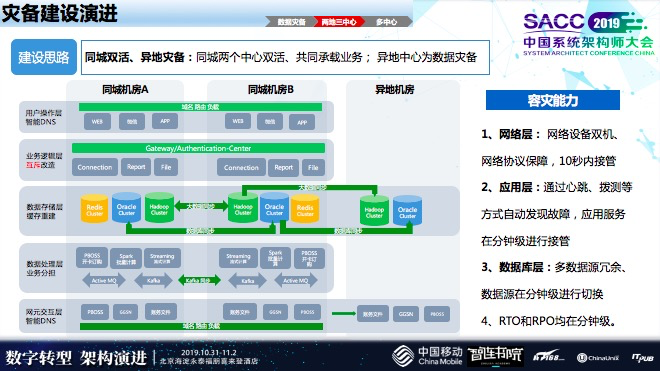
目前,我们正在建设两地三中心,打造同城双活异地灾备,异地机房的备份和前面那一个状况有一些类似,只不过现在多了一些实时的,前面的是每天备份一次。
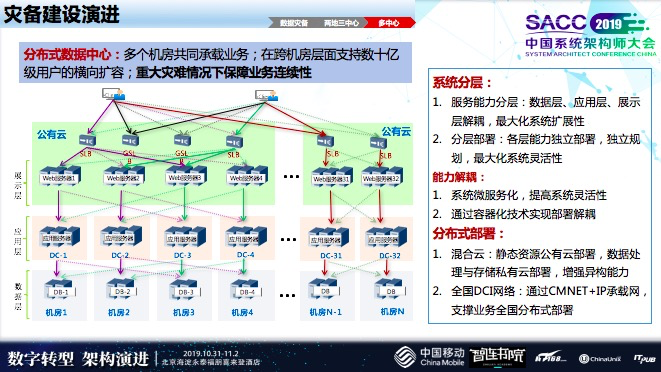
我们计划同城建立双活,大数据和数据库完成实时同步,在和外部交互的状况,通过路由做用户切换,内部应用层做打造,达到同城双活的目的,这部分我们做了一部分验证还没验证完,正在上线,预计年底会投产。我们会用更复杂的混合云来完成架构兼容性的演进。
案例分享
首先,举个例子,比如手机开机、关机,数据或状态变更,会上报到网关上面,接下来,会经过中间层业务传递到上面的平台。物联网设备也一样。
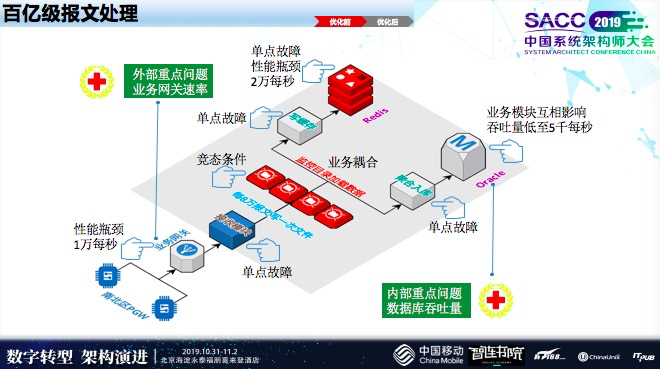
现在,用户量越来越多了,短时间有大量的设备会移动的,像汽车、高铁上面都有很多设备,传感器设备会产生大量数据,这个时候业务网关设备是厂商负责建设的,它收到终端上面的信息会传到我们的平台,这个网关才会传到最终的业务平台上面去,这个时候会存在新的瓶颈,我们一开始不知道这里的问题,后来,通过实际验证才发现,这个地方压力存在一万每秒就存在数据丢失问题。
早期,写了一个文件来完成数据的缓存,后面,上层业务在读这个文件,聚合业务也在读这个文件,这样对业务来说存在一定的条件。最后,会把这个数据存到Oracle里面,还有统计报表、查询业务之间的资源,有互相影响的,影响了一个业务从端到端的吞吐量,总共算起来估计在5000左右,我们当时用户量从上千万开始就已经面临压力了。接下来逐步对它做了演进。
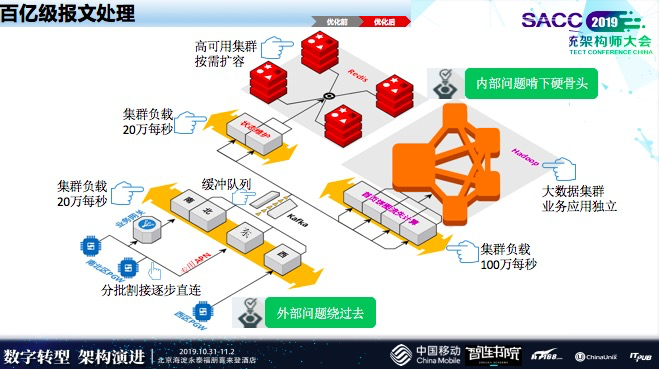
业务网关当时有一个背景,贸易战很早就开始。设备厂商像中兴、华为都受到了影响,只能把它绕过去,我们引用东南西北四个基地从业务网关绕过去,像这些专用客户使用专用的APN,通过我们专用网络来解决它的瓶颈问题。我们接入数据以后,把它缓存下来,后端所有业务通过Kafka完成解网。
后端业务主要两点,第一点,是把Redis单机完成集群的变化,这样进行动态的扩充。计算,最开始也是在Oracle里完成存储,后面,我们基于大数据流式计算来完成数据的业务更迭。
现在最外部压力大概在20万每秒,阿里双十一金额很高,但是订单量真正会引起供销存变化的数据量峰值也才20万每秒,我们承接的固定业务是7×24小时不停的数据,阿里双十一有个峰值后面会降下来,我们20万每秒是缓慢上升的。在我们业务处理时,业务处理大概到100万层面了。
随着业务量上升,随着用户量发展,引起了架构变化。早期架构业务也可以支撑,用户量大了以后带来各种模块出现瓶颈。
心得体会
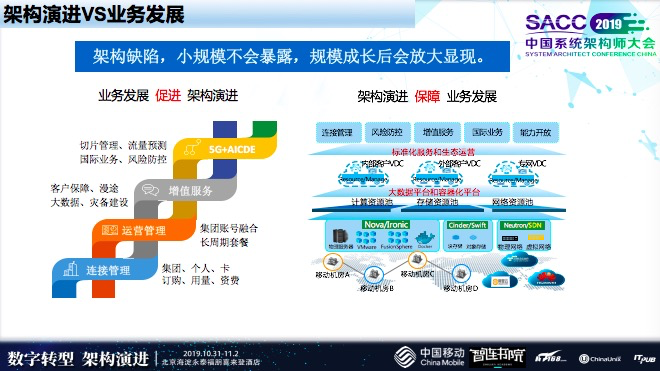
刚才,提到当我们在规模小的时候,架构缺陷不会暴露,当我们规模成长以后这些缺陷会慢慢放大,业务的发展会促进我们架构演进,业务量加大以后去改进、优化它,这些架构演进会更好的促进业务的发展。