

您可能还喜欢:
GAN 实验室:在浏览器中生成对抗网络!
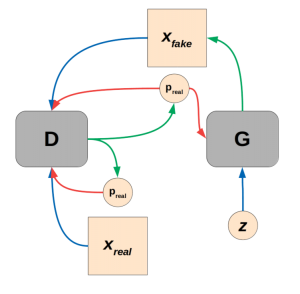
生成对抗网络,简称GAN,是近10年来最令人兴奋的深度学习领域之一。这是根据,除其他外,延勒村MNIST和反向传播的名声。自 2014 年 Ian Goodfellow 等人引入通用数以来,快速进步标志着对抗性培训成为一个突破性的想法,具有以有益、邪恶和愚蠢的方式改变社会的潜力。GAN 培训已用于一切,从可预测的猫发电机到虚构的肖像画家”画”的 GAN 在美术拍卖会上以六位数出售。
所有 GAN 都基于决斗网络的简单前提:一个产生某种输出数据的创意网络(我们的例子中的图像),以及一个能够输出数据真实或生成概率的怀疑网络。这些被称为”生成器”和”歧视”网络,通过简单地试图挫败对方,他们可以学习生成现实的数据。在本教程中,我们将基于流行的完全卷积DCGAN架构构建一个GAN,并训练它为万圣节生产南瓜exxactcorp.com/PyTorch”rel=”nofollow”目标=”_blank”,但您也可以使用TensorFlow(如果这是你舒服的话)。使用两个主要深度学习库的经验已经变得惊人地相似,考虑到今年 2.0 版本中对 TensorFlow 的更改,我们认为这是流行框架的更广泛收敛的一部分,以动态执行,使用 python 代码可选优化图形编译,用于加速和部署。
要为基本的 PyTorch 实验设置和激活虚拟环境,请:
virtualenv pytorch --python=python3
pytorch/bin/pip install numpy matplotlib torch torchvision
source pytorch/bin/activate
如果您已安装 conda 并且喜欢使用它:
conda new -n pytorch numpy matplotlib torch torchvision
conda activate pytorch
为了节省您猜测一些时间,下面是我们需要的导入:
import random
import time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.nn.functional as F
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
架构:DCGAN
我们的GAN将基于DCGAN架构,并大量借用PyTorch示例中的官方实施。”DCGAN”中的”DC”代表”深度卷积”,而DCGAN架构扩展了伊恩·古德费洛原始GAN论文中描述的无监督对抗训练协议。它是一个相对简单且可解释的网络架构,可以形成测试更复杂的想法的起点。
与所有 GAN 一样,DCGAN 体系结构实际上由两个网络组成,即鉴别器和生成器。在拟合功率、训练速度等方面保持均匀匹配非常重要,以避免网络不匹配。众所周知,GAN 培训是不稳定的,可能需要一些调整才能使其在给定的数据集体系结构组合上工作。
在这个DCGAN的例子中,很容易卡住你的发电机出黄色/橙色棋盘胡言乱语,但不要放弃!总的来说,我对这种新突破的作者非常敬佩,在那里,早期糟糕的结果很容易气馁,可能需要一种英勇的耐心。话又说回来,有时这只是一个充分准备和好主意走到一起的问题,事情只需几个小时的工作和计算就可以解决。
生成器G(z)是一叠转置的卷积层,可将长而细小的多通道张量潜在空间转换为全尺寸图像。DCGAN 文件中的下图说明了这一点:
来自拉德福德等人的完全卷积发电机 2016
我们将实例化G(z)作为 torch.nn.Module 类的子类。这是一种实现和开发模型的灵活方法。可以在类函数中设定种子, forward 允许合并一些与简单模型实例无法跳过的连接。
class Generator(nn.Module):
def __init__(self, ngpu, dim_z, gen_features, num_channels):
super(Generator, self).__init__()
self.ngpu = ngpu
self.block0 = nn.Sequential(\
nn.ConvTranspose2d(dim_z, gen_features*32, 4, 1, 0, bias=False),\
nn.BatchNorm2d(gen_features*32),\
nn.ReLU(True))
self.block1 = nn.Sequential(\
nn.ConvTranspose2d(gen_features*32,gen_features*16, 4, 2, 1, bias=False),\
nn.BatchNorm2d(gen_features*16),\
nn.ReLU(True))
self.block2 = nn.Sequential(\
nn.ConvTranspose2d(gen_features*16,gen_features*8, 4, 2, 1, bias=False),\
nn.BatchNorm2d(gen_features*8),\
nn.ReLU(True))
self.block3 = nn.Sequential(\
nn.ConvTranspose2d(gen_features*8, gen_features*4, 4, 2, 1, bias=False),\
nn.BatchNorm2d(gen_features*4),\
nn.ReLU(True))
self.block5 = nn.Sequential(\
nn.ConvTranspose2d(gen_features*4, num_channels, 4, 2, 1, bias=False))\
def forward(self, z):
x = self.block0(z)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = F.tanh(self.block5(x))
return x
G(z)是我们GAN二重奏的创意的一半,而G(z)创造看似新颖形象的学识是大多数人倾向于关注的。没有匹配良好的鉴别器D(x),发电机是无望的。鉴别器架构将熟悉你们中那些在过去已经构建了几个深层卷积图像分类器的人。
在这种情况下,它是一个二进制分类器,试图区分假和真,所以我们在输出上使用 sigmoid 激活函数,而不是用于多类问题的 softmax。我们还在消除任何完全连接的层,因为它们在这里是不必要的。
完全卷积二进制分类器适合用作鉴别器D(x)。
class Discriminator(nn.Module):
def __init__(self, ngpu, gen_features, num_channels):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.block0 = nn.Sequential(\
nn.Conv2d(num_channels, gen_features, 4, 2, 1, bias=False),\
nn.LeakyReLU(0.2, True))
self.block1 = nn.Sequential(\
nn.Conv2d(gen_features, gen_features, 4, 2, 1, bias=False),\
nn.BatchNorm2d(gen_features),\
nn.LeakyReLU(0.2, True))
self.block2 = nn.Sequential(\
nn.Conv2d(gen_features, gen_features*2, 4, 2, 1, bias=False),\
nn.BatchNorm2d(gen_features*2),\
nn.LeakyReLU(0.2, True))
self.block3 = nn.Sequential(\
nn.Conv2d(gen_features*2, gen_features*4, 4, 2, 1, bias=False),\
nn.BatchNorm2d(gen_features*4),\
nn.LeakyReLU(0.2, True))
self.block_n = nn.Sequential(
nn.Conv2d(gen_features*4, 1, 4, 1, 0, bias=False),\
nn.Sigmoid())
def forward(self, imgs):
x = self.block0(imgs)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block_n(x)
return x
我们还需要一些帮助器函数来创建数据加载器,并根据 DCGAN 文件中的建议初始化模型权重。下面的功能返回一个 PyTorch 数据加载器,其中包含一些温和的图像增强功能,只需将其指向包含图像的文件夹。我正在处理来自Pixabay的一个相对较小的免费图像,因此图像增强对于从每个图像中获取更好的里程非常重要。
def get_dataloader(root_path):
dataset = dset.ImageFolder(root=root_path,\
transform=transforms.Compose([\
transforms.RandomHorizontalFlip(),\
transforms.RandomAffine(degrees=5, translate=(0.05,0.025), scale=(0.95,1.05), shear=0.025),\
transforms.Resize(image_size),\
transforms.CenterCrop(image_size),\
transforms.ToTensor(),\
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)),\
]))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,\
shuffle=True, num_workers=num_workers)
return dataloader
要初始化权重:
def weights_init(my_model):
classname = my_model.__class__.__name__
if classname.find("Conv") != -1:
nn.init.normal_(my_model.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
nn.init.normal_(my_model.weight.data, 1.0, 0.02)
nn.init.constant_(my_model.bias.data, 0.0)
这就是函数和类。现在剩下的就是把这一切与一些脚本(以及超参数的无情迭代)联系在一起
# ensure repeatability
my_seed = 13
random.seed(my_seed)
torch.manual_seed(my_seed)
# parameters describing the input latent space and output images
dataroot = "images/pumpkins/jacks"
num_workers = 2
image_size = 64
num_channels = 3
dim_z = 64
# hyperparameters
batch_size = 128
disc_features = 64
gen_features = 64
disc_lr = 1e-3
gen_lr = 2e-3
beta1 = 0.5
beta2 = 0.999
num_epochs = 5000
save_every = 100
disp_every = 100
# set this variable to 0 for cpu-only training. This model is lightweight enough to train on cpu in a few hours.
ngpu = 2
接下来,我们将实例化模型和数据加载器。我使用双 GPU 设置快速评估几个不同的超参数迭代。在 PyTorch 中,通过在 torch.nn.DataParallel 类中包装模型来在几个 GPU上训练是微不足道的。不要担心,如果你的所有GPU都捆绑在追求人工智能,这种模式是轻量级的,足以在合理的时间(几个小时)CPU 上训练。
dataloader = get_dataloader(dataroot)
device = torch.device("cuda:0" if ngpu > 0 and torch.cuda.is_available() else "cpu")
gen_net = Generator(ngpu, dim_z, gen_features, \
num_channels).to(device)
disc_net = Discriminator(ngpu, disc_features, num_channels).to(device)
# add data parallel here for >= 2 gpus
if (device.type == "cuda") and (ngpu > 1):
disc_net = nn.DataParallel(disc_net, list(range(ngpu)))
gen_net = nn.DataParallel(gen_net, list(range(ngpu)))
gen_net.apply(weights_init)
disc_net.apply(weights_init)
培训
生成器和鉴别器网络在一个大环路中一起更新。在讨论之前,我们需要定义损失标准(二进制交叉熵),为每个网络定义优化器,并实例化一些列表,我们将用它来跟踪训练进度。
criterion = nn.BCELoss()
# a set sample from latent space so we can unambiguously monitor training progress
fixed_noise = torch.randn(64, dim_z, 1, 1, device=device)
real_label = 1
fake_label = 0
disc_optimizer = optim.Adam(disc_net.parameters(), lr=disc_lr, betas=(beta1, beta2))
gen_optimizer = optim.Adam(gen_net.parameters(), lr=gen_lr, betas=(beta1, beta2))
img_list = []
gen_losses = []
disc_losses = []
iters = 0
培训循环
训练循环在概念上非常简单,但在单个代码段中需要占用一点时间,因此我们将将其分解为几个部分。从广义上讲,我们首先根据对一组真实和生成的图像的预测来更新鉴别器。然后,我们将生成的图像馈送到新更新的鉴别器,并使用来自 D(G(z)的分类输出作为发电机的训练信号,使用实际标签作为目标。
首先,我们将输入循环并执行区分器更新:
t0 = time.time()
for epoch in range(num_epochs):
for ii, data in enumerate(dataloader,0):
# update the discriminator
disc_net.zero_grad()
# discriminator pass with real images
real_cpu = data[0].to(device)
batch_size= real_cpu.size(0)
label = torch.full((batch_size,), real_label, device=device)
output = disc_net(real_cpu).view(-1)
disc_real_loss = criterion(output,label)
disc_real_loss.backward()
disc_x = output.mean().item()
# discriminator pass with fake images
noise = torch.randn(batch_size, dim_z, 1, 1, device=device)
fake = gen_net(noise)
label.fill_(fake_label)
output = disc_net(fake.detach()).view(-1)
disc_fake_loss = criterion(output, label)
disc_fake_loss均值().项()
disc_loss = disc_real_loss = disc_fake_loss
disc_optimizer.步()
请注意,我们还跟踪假批次和真实批次的平均预测。这将通过告诉我们每次更新后预测如何变化,让我们以一种直接的方式来跟踪我们的培训的平衡程度。
接下来,我们将使用实际标签和二进制交叉熵损耗根据鉴别器的预测更新生成器。请注意,我们正在更新生成器基于鉴别者的错误分类假图像为真实。
此信号为训练生成更好的梯度,而不是最小化鉴别者直接检测假货的能力。令人印象深刻的是,GAN 最终可以学习基于这种类型的决斗丢失信号生成逼真内容。
# update the generator
gen_net.zero_grad()
label.fill_(real_label)
output = disc_net(fake).view(-1)
gen_loss = criterion(output, label)
gen_loss.backward()
disc_gen_z2 = output.mean().item()
gen_optimizer.step()
最后,还有一点家务,以跟踪我们的训练。平衡 GAN 培训是一种艺术,从数字中并不总是显而易见的,您的网络是否有效学习,因此最好偶尔检查图像质量。另一方面,如果打印语句中的任何值转到 0.0 或 1.0 机会,您的训练已崩溃,最好使用新的超参数迭代。
if ii % disp_every == 0:
# discriminator pass with fake images, after updating G(z)
noise = torch.randn(batch_size, dim_z, 1, 1, device=device)
fake = gen_net(noise)
output = disc_net(fake).view(-1)
disc_gen_z3 = output.mean().item()
print("{} {:.3f} s |Epoch {}/{}:\tdisc_loss: {:.3e}\tgen_loss: {:.3e}\tdisc(x): {:.3e}\tdisc(gen(z)): {:.3e}/{:.3e}/{:.3e}".format(iters,time.time()-t0, epoch, num_epochs, disc_loss.item(), gen_loss.item(), disc_x, disc_gen_z1, disc_gen_z2, disc_gen_z3))
disc_losses.append(disc_loss.item())
gen_losses.append(gen_loss.item())
if (iters % save_every == 0) or \
((epoch == num_epochs-1) and (ii == len(dataloader)-1)):
with torch.no_grad():
fake = gen_net(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True).numpy())
np.save("./gen_images.npy", img_list)
np.save("./gen_losses.npy", gen_losses)
np.save("./disc_losses.npy", disc_losses)
torch.save(gen_net.state_dict(), "./generator.h5")
torch.save(disc_net.state_dict(), "./discriminator.h5")
iters += 1
可能需要一点工作才能得到可传递的结果,但幸运的是,我们轻微的小故障,在现实中,是更可取的放大蠕变。此处描述的代码可以改进,但应该适用于分辨率较低的合理合理的千斤顶灯。
训练进度后约5000更新纪元。
希望上述教程能刺激您对 GANs、万圣节工艺品或两者的胃口。掌握了我们在这里构建的基本 DCGAN 后,尝试更复杂的体系结构和应用程序。训练通用仍然是一门巧妙的科学,平衡训练是棘手的。使用ganhacks的提示,在获得适用于数据集/应用程序/想法的简化的概念验证后,一次只添加少量复杂性。祝你好运和快乐的训练。